“This team, oh they will work hard to meet any target, no matter how impossible it seems.”
“Folks, we are committed to this deliverable, the product team has already promised the customers, we need to somehow make it happen.”
“If we pull this off by release date, we will be hailed as heroes”
“It will be hard, but the team will figure out how to get it done in time.”
“Team, just for this release, this one time, I am going to ask you all to work a few nights and weekends. We will even bring in lunch if needed.”
My guess is most of us have heard these or even said them(I know I have done both). You might say that these statements represent management that puts short term targets ahead of the well being of the people being managed. You might even argue that this short term thinking undermines long term predictability and quality of the product being delivered. But then, so what, the team pulls the rabbit out of the hat, we meet our commitments, pat ourselves on the back and repeat the cycle again. What is wrong with that? We are getting things done. We are feeling like heroes. The team is able to show management, how awesome it is. Every level of management can do the same to the level above. We are all getting in line for bonuses and promotions. Could this really be a bad thing?
What about the people? Well, if we stop pushing our people to the edge, does not mean our competition will. This means we will not be working miracles, but our competition will be. That cannot be good. If everyone, including our competition is relying on people put in extra hours, these people don’t have much of an option, do they? What are they going to do? Quit? Quit, and then go somewhere else where they have to do the same thing. It does not matter to us if they quit anyway, we can always hire replacements. Maybe someone that costs us less. We will help them pack up there stuff and kiss them goodbye as we look for replacements. Developers are dime a dozen.
It is not just that we are afraid of failing in comparison to our competition. Even within our organization, my team, me as a manager, my boss, my boss’s boss, will all seem like people who cant get sh*t done. If I seem like a manager that cannot get sh*t done, I will never get promoted. If my boss looks like she/he cannot get sh*t done, I will never ever get promoted. Even if promotion and bonuses were not in the picture, I have a responsibility to push the team to get results. Once we have made a commitment it has to be kept, regardless of how much new information and surprises show up.
We have no right to tell our bosses and customers that we are going to miss the deadline, when there are unused hours of the day that we can squeeze out of developers. Deadlines motivate people, and by motivate I mean gives them the incentive to work longer hours as the deadline gets nearer. Here is an idea — Let us go Agile. This way we work in sprints of 2 weeks. Which means, deadlines, every 2 weeks. Let us make the sprint so often, they will forget that they ever walked. We cant get ahead by walking, we have to be sprinting at all times.
Of course, things happen, people have to take time off, new work comes in, customer issues pop up, we get pulled into estimation meetings etc. Regardless of all this and regardless of scope creep and discovering that things were more complex than we thought, we have to meet our deadlines. They are called deadlines for a reason. We cant extend the deadline, we cant cut scope. There are only two options. Throw more people at it, or, “work harder”. People are expensive and we have other areas that are struggling to meet commitments anyway. That leaves one option — “work harder”.
We have faith that we can make anything happen. We don’t need predictability, we make our own predictability. If we say that a certain feature will be delivered in a certain release, it will be delivered one way or another. Our predictability is built by the team working its tail off. It does not require any of the fancy “sustainable pace” or “stable systems” talk. Feel free to take your predictability and go home. We are going to meet our commitments anyway.
There are greater things at stake with this release. We do not really have time to waste on this “process improvement” that might not work out anyway. We can talk about that next release when we have less pressure. This is the last release where we will push the team this way. From next release onward, we can look at ways to make things better. We know we have said that a few times in the past, but this time we really mean it. Since we already know the capacity of the team from this release, we will commit to the amount of work we are getting done this release for the next release. We cannot tell our customers and bosses that we will do less, reducing capacity is unacceptable. Yup, next release will be different.
We trust our teams, they are empowered. They are fully empowered to figure out how they are going to meet the commitments that we have made for them. Our team is a hard-working team. They can do the impossible. They will never let the management of the team look bad. The management, in turn, would never let senior management look bad. When the team does the impossible, we will celebrate them, give them compliments, take them out for a happy hour. After all, they need to be rewarded and if we don’t, they might not be inclined to do this again. “This team, oh they will work hard to meet any target, no matter how impossible it seems.”
In 1968, Melvin Conway wrote the paper “How Do Committees Invent”. One of his observations in that paper (among numerous interesting ones) was declared Conway’s Law. Conway’s Law states — Any organization that designs a system (defined more broadly here than just information systems) will inevitably produce a design whose structure is a copy of the organization’s communication structure.
Conway talks as much about the software that is produced as he does about the organizational structure producing it. Much has been written in support of micro-services architectures, using Conway’s Law as a base premise and justification. These articles focus on Organizational design at the team level. They propose small teams that work on independent small services. I do not have any qualms with these recommendations. They do, often, ignore the impact the larger org structure can have on the software being produced. If team structure determines the design of the software and interfaces, the broader org structure determines the quality of customer outcomes achieved.
Conway’s Effect on Products
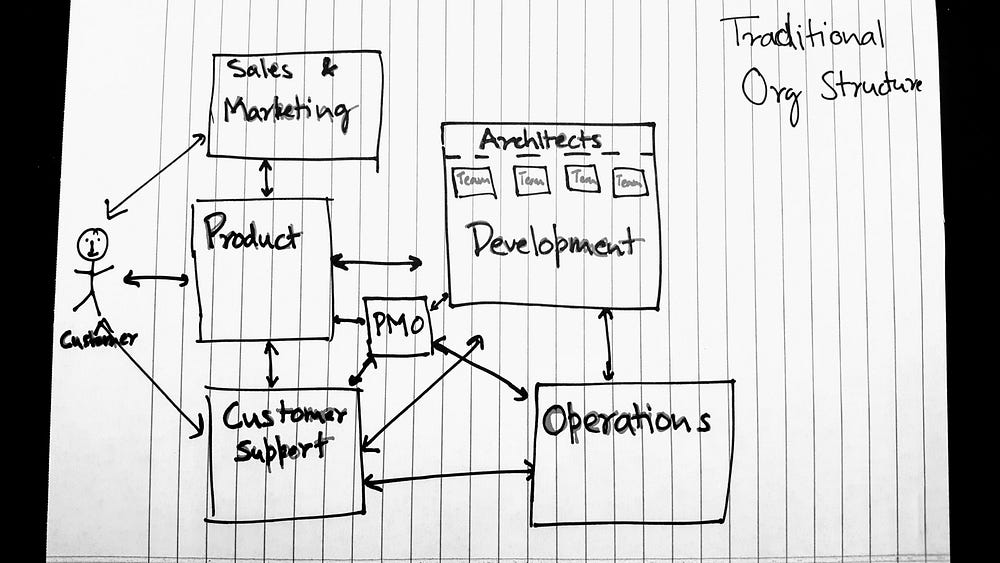
Consider the structure of an organization as shown below.
The first thing to notice is that the customer (on the left hand side of the drawing) has no direct line to the development team. The vice-versa is true as well. Customer has to go through Product or Support to get to development. Development teams themselves have to go through either Product, PMO, Operations or Support to get feedback from customers. Conway’s Law, when applied to this setup would mean that since developers are a one or two layers removed from the customers, the features and products they produced are likely to be one or two steps removed from the real needs of the user.
Each group has multiple masters. Product is directly responsible for satisfying feature and enhancement requests from Customers, Sales and Support. Product is also responsible for providing structured requirements and priority updates to the Development teams as well as PMO. This forces the Product department to create a mixed set of priorities which most likely is not directly representative of the priorities of the customers. Development teams, already one step removed, receive this mixed list of priorities. For the dev teams though, this is just one “customer”. They also have to satisfy directly received tickets from Support, provide timelines to PMO, deployment requirements to Operations all while satisfying the overriding directives from Architecture.
Each group also has its own objectives and incentives. Sales wants flashy items to sell, Customer Support wants low time to resolution on calls, Product wants maximum number of complete features, Development wants new technology and maintainable code and Operations wants easily deployable, portable and stable products. Everyone is pulling in slightly different directions, with customer satisfaction, delivery of customer value and fulfillment of customer outcomes lost somewhere in the middle of the tug-of-war. All this is happening, while each member of each department is doing there best and working hard to achieve the department’s objectives.
The lack of alignment sets Conway’s Law into motion. The result of this is usually a confused (or an increasingly confusing) product. The separate departments push their separate agendas onto the end product. The product, as a consequence, has lots of features, but most of them are incongruent and rarely used. With the teams developing the product being a couple of layers removed from the customers, this feedback rarely makes it back to them. Even if it does they are already on to the next thing on some other department’s priority list. The competing and misaligned priorities for each department leads to the actual customer priority being lost in the shuffle. Each department firmly believes they are doing the best thing for the customer and the misaligned priorities result in customer’s best interests being only half-fulfilled at best.
Conway’s Effect on Process
It is not just the priorities that are mismatched, the departments have different capacities and speed of production as well. This would mean finished work sitting between departments in queues waiting to be picked up. It could also mean departments being starved for work as they are waiting for deliverables from other parts of the system. Instead of the process enabling a lean flow of value to the customer, the value generated sits in queues despite everyone doing there best to achieve their department’s goals. The structure and mismatched capabilities make flow very hard to attain. If we restate Conway’s Law in terms of process, it would fit perfectly — Any organization that follows a process will inevitably produce a process whose structure is a copy of the organization’s communication structure.
Even within, what is supposed to be a cohesive team, the separation of concerns persists. This is usually because the departments themselves are not in alignment on objectives, priorities or incentives.
We can try to solve this be moving folks from the product and operations teams onto the development teams. This can at times work, but as long as the individuals serve separate masters and have varied incentives, bad, inefficient processes will emerge. If BAs and PMs are made a part of the development team, but still serve a separate product department, they are receiving mixed signals. Many times, not always, they tend to act as teams within the larger team. Due to this, there is a “not my job” and “over the wall” mentality that develops on the team. High level requirements are the PM’s job, writing stories is the BA’s job, writing and testing code is the developer’s job and deploying the code to production is the OPS person’s job. Even within, what is supposed to be a cohesive team, the separation of concerns persists. This is usually because the departments themselves are not in alignment on objectives, priorities or incentives.
One quick note on DevOps. If you put a person from the operations team onto the dev team and all that person does is OPS work with no interaction with the devs, it does not mean that you are “doing” DevOps. For DevOps, developers take on operations responsibilities and operations folks help out with development.
With separate objectives and incentives, the queues will still exist. Value will still sit in these queues and becomes stale. Stories and features would be coded and tested weeks or months after they are written. The same will happen for deployment activities. Finished work will not make it to customers months after it was done. This would cause disappointment for any customers of this process as their wait times keep increasing. An increase in inter-department wait times leads to increased mistrust among already segregated departments. Departments do not believe that their partners are moving fast enough and push more and more work downstream. Sales does it to Product, Product to Development and Development to Operations. The overriding belief becomes — “in order to get more done, we need to push more work onto them”. This is where Little starts helping Conway.
Little’s Law
In 1961, John Little provided mathematical proof of the queuing formula that has come to be known as Little’s Law. In the development world, it is commonly expressed as follows —
Here Lead Time(or Cycle Time) is the amount of time it takes for a work item (task, story feature, initiative etc.) to get done. Work In Progress (WIP) is the total number of items in progress. Throughput is the number of items getting done per unit of time (per day, per week, per month etc.). Little’s Law is a truth of nature. It is mathematical fact and is inescapable.
The simple conclusion from Little’s Law is that if we have a consistent speed of getting things done, the amount of time it takes to do each thing, is directly proportional to the number of things we are working on. In other words, if we want to get things done faster, we need to work on fewer things. One important thing to remember is that this applies at every level of granularity. It applies at the story level, the feature level and the initiative level.
Conway and Little — Putting the WAR in softWARe since 1960s.
As we have already discussed, one of the consequences of an organization splintered along specialization departments is sibling departments pushing more and more work onto each other. Unfortunately, according to Little’s Law this only makes things worse. The more things we take on , the longer each individual thing takes. As opposed to delivering individual bits of value to the customer, we work on everything and deliver nothing. Since everything takes a long time, we try to subvert the process by having “fire lanes” and high priority expedites. Unfortunately, these are not exempt from Little’s Law. They only increase the WIP. Also, because we have done nothing to increase our throughput, all this does is increases our cycle times for each deliverable. Increased cycle times, fuels more frustration, greater mistrust and increased friction between departments. Once again, the customer and, as a consequence, the company comes out as the loser in the struggle.
Conway And Little Are Your Friends
So far we have only explored the negative effects of Conway’s Law and Little’s Law. The fact is that these two are our friends. They can help us design our organizations for success and then execute on the design. First let us define what success means, then design the organization around that definition of success and finally establish flow to become successful. Conway will help us design the organization and Little will help us establish flow.
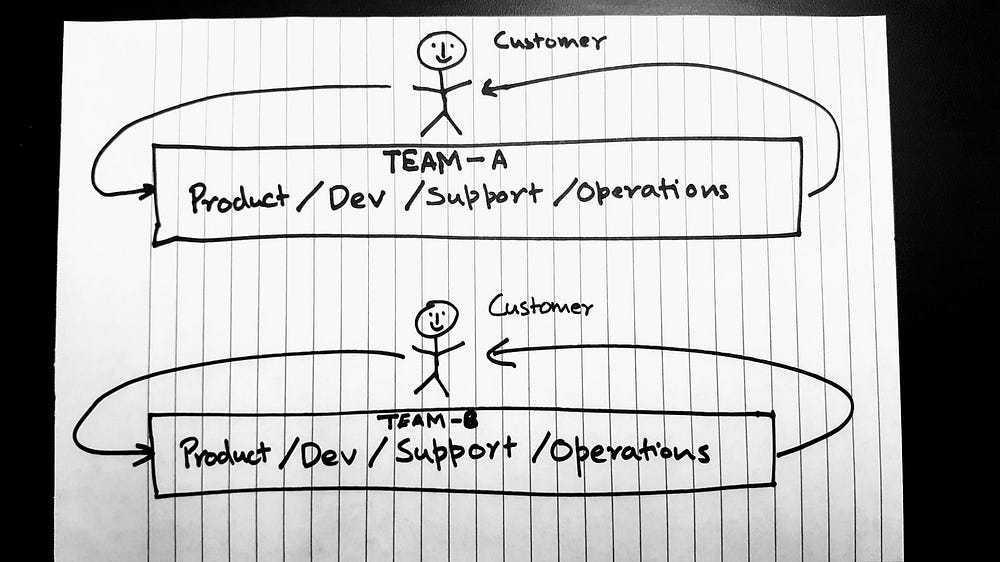
What if we took a very simple definition of success — Achieve positive outcomes for the customers. This would require creating alignment between all the moving parts of the organization. The sketch below is how I would propose we create an organization to achieve success.
In this organization every team is actually cross-functional. Every team member can be involved in every activity. Product owners can bring developers along for customer interviews. Devs can break down stories, BAs can test, and we are actually doing DevOps where developers are taking care of operational needs as well. Each team has every capability needed to get requirements, create functionality, deliver code to production, receive feedback and support the product. A team is responsible for that entire life-cycle of that particular piece of functionality. Everyone on the team is able to get user feedback and help in reacting to that feedback.
Each team is a fully cross-functional startup. They are able to move fast and support each other when things start to back up. There is no segregation of responsibilities. Sure there are “roles” that signify expertise, but people are encouraged to help in every part of the process. There is a singular objective for the entire team — Help customers achieve positive outcomes. The team can be as large or as small as needed to achieve this objective. They report into the same department. They are all incentivized to do the same thing — deliver customer value. We get rid of hand-offs and work with continuous customer validation of the artifacts produced. There are no competing masters, just a team being able to take care of customer needs all by itself.
Unlike Little’s Law, which is mathematical fact, Conway’s Law can be (temporarily) escaped. You can keep the traditional structure and drive alignment across departments. Since that is root of the problem, once cross department alignment is achieved everyone will naturally act as a single team. The problem is the energy required to maintain the cross department alignment. As soon as these departments start having their “all team” meetings, department objectives, execution standards and their own bonus plans, Conway will again take over. The decision to make is — Do we go through the pain of formalizing a cross functional org structure or do we continuously spend the energy to maintain alignment across departments?
Conway just helped us set up an organization and establish a process (at a very high level). We can still run into problems if we do not pay attention to Little. In order for us to establish flow and quickly deliver value for validation, we need to go back to Little’s Law. We need to continuously observe the amount of work flowing through these teams. The teams should take on only as much work as can flow through their process. As Little’s Law tells us, with stable throughput, the more things we work on, the longer things will take to get done.
Little’s Law makes us focus on being productive as opposed to being busy.
It is likely that in the organization proposed here, there would be large teams. Also, teams would not consider something done until the customer has validated it. These two things combined will have a tendency for teams to take on more work than they should. In order to achieve regular validation and delivery of functionality, Little tells us that we have to resist this urge. Work on as few things as possible, so that each individual work item gets delivered as quickly as possible. This will get the energies of the entire team focused on getting those few work items delivered. As soon as one item is delivered, the team can figure out the next highest priority and start working on that one. Thus, creating a stable, predictable system that delivers functionality regularly and is not derailed easily by external pressures and changes. Little’s Law makes us focus on being productive as opposed to being busy.
When things do change in terms of priority, very few items are put at risk. In fact, if the team is delivering things regularly(hourly, daily, weekly…), nothing might be put at risk. This is because the new highest priority can be picked up for work as soon as the next (currently active) item is delivered. Thus, we can use Little’s Law to eliminate a lot of waste due to changing priorities.
When we work on very few items, they do not wait in queues between departments or individuals. As we are working on these together, these queues either do not exist or are minimal. Conway and Little have together helped us eliminate the waste that accumulates due to valuable work sitting in these queues.
This Is Hard
It is, primarily because this type of thinking requires people to give up power. It simplifies the structure where the “product design, development and delivery” team has all the power and most hierarchies are dead. If the folks in the organization are attached to wielding control and personal authority, this would be such a hard change that people might not even attempt it. Just as listening to Conway would be hard for power addicted managers, listening to Little will be hard for the individual contributor superstars. There is no individual glory anymore. There are no martyrs and heroes. The teams work together, across erstwhile functional boundaries to do the best for our customers.
There is a good amount of giving up of personal egos that has to happen here. Everyone has to accept a flatter organization where we are all working together to achieve our most important goal — Positive Customer Outcomes.
Here is the other hard thing. If you notice, I have eliminated PMO and Architecture from the second org sketch. It is possible that entire departments would be eliminated and handed “demotions” to be a part of the value delivering teams. It might just turn out that Little will eliminate the need for PMO and Conway would encourage us to turn Architects into developers that work towards customer outcomes. There is a good amount of giving up of personal egos that has to happen here. Everyone has to accept a flatter organization where we are all working together to achieve our most important goal — Positive Customer Outcomes.
Conway and Little can be lethal for traditional power structures and individual glory. But, on the other hand, they can save your organization as opposed to killing it.
Imagine you have been tasked to produce a brand new product. You have been asked to create a project timeline and given high-level requirements. All initial estimates point for this to be a 3-year project. How would you go about developing this product? For the sake of this post, we will consider two different approaches to the same project. First, is the more traditional big bang approach. One where the deadline is set three years out. We know there is a lot of work that needs to get done and our best estimates tell us that this will be done three years from now. Second is the more agile, iterative approach. Here we believe that we can deliver some minimal functionality in 3 months, and push out updates every week or so. We still estimate that it will take us three years to build the initially requested functionality. Let us take a look at what these look approaches look like in real life. We will first play this out for the big bang three-year project and then the iterative one.
Big Bang
This is the approach where at the beginning of the project we know what we are going to build and we have estimated out that it will take us three years to build it. We are going to work through the next three years and ultimately deliver the entire project to the customer.
Product Direction
A three-year plan has a very basic assumption built into it - We know everything that the customers want at the beginning of the project. Of course, we leave room for things coming up, but in general, we know the things we are going to accomplish over the next 3 years. These are the things that we have started to promise our customers. They will be available when the first paid version of the application ships. If the competition forces us to change our course or new compliance requirements come up, we either push the team harder to make the same date or we disappoint our customers. There is little room for surprises and every surprise is a threat to the ship date. As the project goes on, the competition comes up with new innovations. Someone inevitably mentions artificial intelligence or big data or meta-platforms or something else that we really need to be doing halfway into the project. Seeing that what seemed as the state of the art when the project was started is not the buzz anymore, these new concepts become part of the scope. The date cannot move much though because it has been promised. We ask the teams to go re-estimate and figure out how to fit everything into the timeline.
We might set up internal milestones for the teams, but engineers are a lot smarter than we give them credit for. They know that these internal dates are bogus. Especially when the internal dates are not met and still the final date doesn't shift. They quickly realize that the internal milestones are just mini death marches to ensure that the developers are moving as fast as possible. Managers love these fake targets as it helps them show progress and feel good about hitting them. The developers, though, pretty soon catch on to the smoke and mirrors when the end line is not moved despite having to work nights and weekends for these internal targets. Rarely are our initial assumptions ever challenged and things removed from the roadmap. Even if we have to go on death marches to meet internal dates, the scope and date for the final delivery are fixed.
Prioritization
Since we have 3 years to finish everything, there is no real priority on anything. It does not matter what we work on first because everything will be delivered at the same time. We pretend to have a priority order to give our project some structure. In fact, Project Managers have all the fancy portfolio management tools, excel spreadsheets, Gantt charts showing that there is an order in which these things should be accomplished and also showing that their jobs are justified. But these charts, in reality, mean nothing. There is very little customer validation of what is being built. No customer is expected to use this product till it is "finished". Which means it does not really matter if you work on workflow before any functionality that requires workflow even exists.
Since everything is important and there is no intermediate delivery, multiple teams start multiple features at the same time. These include features that might be a very low priority for the project, but since we have the people available, and three years in front of us, why not? Everything needs to be done by the end of it anyway. This often results in multiple 80% done features as the scheduled date nears. This is the point where we start cutting corners on code and product quality. Starting multiple things without any real prioritization at once puts them all at risk.
We have started with the assumption that everything that we are working on is necessary to be done and at no point are we willing to question those assumptions. As long as all the features we said would get done are done, it does not matter which ones were the most useful. It also does not matter if we worked on something for multiple months and no one ever used it because it got delivered on time. We will probably never realize that no one is using it anyway since our goal was to ship the feature within the 3-year timeframe, not solve a customer problem.
(Big Up-Front) Design
As the company is making a huge investment by embarking on a three-year project, everything has to be perfect. There is a good amount of time spent doing up front analysis and design. Multiple months might be spent doing research even before any code is written. Most often a lot of this analysis is thrown out soon after we actually start writing the code. It is usually discovered that either the design was untenable or our initial customer validations of the actual screens told us that the analysis was wrong. Expert consultants might be brought in to help create the perfect modern architecture. This is where the Architecture group shines. The architects have the pressure of building the perfect architecture on which this 3-year plan is to be executed. An architect is a very dangerous animal. He or she is often a software engineer who has not written any customer facing software in a while. The Architect does not work on teams but instead designs and executes the architectural vision. This type of project is perfect for the architect. This is the opportunity to play with new patterns and to do green-field research. Architecture groups can take months to produce something and no questions will be asked because, in order to be successful, the product architecture has to be perfect.
The resulting architecture is cumbersome to work with as it tries to solve every imaginable problem the project would ever face. Solving for the future almost always ends up slowing down the present. Instead of the architecture evolving with the product and the customer's needs, it is running ahead in its own pursuit of perfection. We don't know, for sure, if these are actually problems that need to be solved. We only have assumptions that the customers are going to need these solutions, leading to premature optimizations. Per Donald Knuth - "premature optimization is the root of all evil (or at least most of it) in programming". Developers slow down tremendously as the architecture is continuously in their way. Instead of making development easier all the extra technical requirements have slowed progress to a grinding halt. It takes dozens of professional developers months to produce the same functionality a couple of college students could have produced in a week.
Premature optimization is the root of all evil (or at least most of it) in programming. - Donald Knuth
Developer Morale
Managers are baffled by the slow pace. Deadlines and promises are now at risk. We need to take the developers aside to re-estimate to understand the risk. We need to have meetings and surveys about how to fix things. The developers usually respond to these surveys honestly the first couple of times. They express their frustration with the process, the architecture, the way the project is being managed etc. Since this hits directly at the people evaluating the survey, the results are mostly ignored. A couple of appeasing words might be said to the developers, but we don't really have time on this project to make sweeping changes. We have already invested multiple months in our current strategy, we can't change it regardless of how bad the people on the ground think it is.
Developers then try to fix this by trying to work around the architecture or by trying to influence change in the architecture. They come up with proposals to make things go faster and they usually involve dumping many of the complicated architectural components. Suggestions might even involve switching technologies to ones that lend themselves better to the project at hand. These suggestions are given some thought but usually discarded. They threaten the reign of the architects and also the timeline at least in the short term. Developers cannot be made to think that they know better, otherwise the project will run out of control.
Most successful and driven developers like to see the products they build being used. Developers derive fulfillment not just from solving problems, but also by producing customer value. If a developer has to wait up to three years for the product to see the light of the day, morale will invariably decline. The flip side of the argument is that if we have developers that do not derive fulfillment from delivering customer value - Should we really have them on the team?
Getting feedback early and often helps the developers be connected to the users and results in software that is much better at solving business problems. It also results in developers who want to solve business problems and deliver these solutions as soon as possible. In the case of the three-year project, we are actively telling our developers to not care. We are telling them to put their heads down and keep plowing through using the frameworks and technologies they have been told to use. It does not matter whether what you worked on was useful or not, here is the next story or feature to start. Can you not see we have a deadline, we don't have time to stop and verify. We might even run an Alpha program that would not change the course of what we are working on by much.
(Long Term) Predictions
Almost all of these issues stem from the fact that right at the beginning of the project we assumed that we knew exactly what we want to do over the next 3 years. We have made predictions that are three years out and have started making bets on them. We have made promises that need to be delivered on. Managers have promised progress to directors, who have promised a product to the C-Level. The C-Level and sales team have gone out and already sold the product with a full feature set to the customers. There is a lot of disappointment to go around if this does not happen. Heads will roll. Our Gantt charts tell us that things are slipping but we believe we can make it. If we add four people and increase our per person throughput by 50% we will definitely make it. We are projecting multiple years in advance at the same time as we have trouble meeting our internal monthly milestones. Everyone on the team knows that the project is heading for disaster but they have been beaten back enough that they don't want to be the bearers of bad news. After all, heads will roll. We are trying to predict the impossible - How much can we get done in 3 years? Once we have made the prediction, we are sticking to it, because promises have been made and now we cannot back off of our predictions. The interesting part is, even if we build everything we said we would, there is no guarantee that we have actually built a successful product since it has never been tested in the field.
Ending The Project
The three-year project has a great cost involved with terminating it early. There is nothing to show as a result. We have a whole bunch of unfinished features that don't work cohesively together. It is not a product at any point of time before the very end. Exiting the project in the middle seems to only have costs and no benefits. We cannot sell a half-finished product and since we have spent all this money in building this half-product, we might as well bite the bullet and finish this. We are living smack in the middle of "sunk cost fallacy" land. The length of the project makes it very likely that we will have to make this decision. Market forces change rapidly. Assuming that we can hold a course for 3 years amongst these changes is irresponsible on the part of the management at any company.
Let us see how the same project if done in an iterative manner, progresses.
Iterative
In this case, we would assume that the project has the same initial objective - To deliver a product in 3 years. We are instead going to take a different approach. We are going to aim to deliver a much smaller feature set in 3 months. We will then deliver incremental bits of functionality as often as it is completed (every month, week or day as appropriate).
Product Direction
Product direction, in this case, starts with the question of what is the minimal functionality we can deliver to the customer. This is the direction for the first 3 months. Once the MVP is out there, the product direction actually becomes agile. We take user feedback, strategic direction and market forces all into account o determine the next most important thing to deliver. It could be improving existing functionality, adding new features, responding to changing market conditions, any of the above. The product direction emerges. In fact, many of the things that we initially thought would be valuable when we started might never end up getting done because we would be agile with our product direction to produce that what our customers really want. We would not waste time building things we think our customers want and would instead quickly deliver and validate if we actually built the right thing. We would adapt and learn and even delete features if our customers don't use them.
Prioritization
Our prioritization is now based on real use. We only work on the very limited scope that is to be delivered next. We have a sharp focus on the next most important customer request. Instead of everything being equally important and delivered at the same time, we are actually delivering software incrementally. This forces us to prioritize from the user's perspective. Instead of building a workflow that is seven levels deep, we wait for the business case for just enough workflow to become evident and then implement just what is needed by the customers. The number of assumptions in prioritization starts to dwindle to the assumptions only about the very next thing, and we validate or invalidate those assumptions as soon as often as we deliver.
The point about focus is worth repeating. You could probably get more value out the door with fewer people and in less time if the entire team is focussed on just the next deliverable as opposed to a single 3-year long deliverable. Alternate priority conversations don't ever interrupt current work. We don't pull the team off in the middle of solving business problems to estimate how long something else would take. When capacity is available, we prioritize just in time and pull the next most important thing. We don't spread ourselves thin and instead get focussed on the next thing to deliver.
Design
Analysis, design, and architecture all happen just in time as well. Architects act more as tech leads and enable the other developers on the team to achieve outcomes faster. The focus is on delivering the next valuable piece of software and not on building the perfect architecture. We architect knowing that we are making assumptions about what the next thing of value is. That means that while we require the flexibility to be able to change course, we also need the flexibility to delete entire pieces of the architecture without adversely affecting the customers. This leads to an architecture that is both emergent and flexible. It does not hinder today's progress and enables tomorrow's extension of functionality. We are wary of looking too far into the future because we don't know what we will need to build. If the current priority does not require it, we don't write it. We refactor, learn and adapt as time moves on, in order to make delivery of value as easy as possible. This is where the architects actually earn their technical swagger. Not in long-running pipe dream tech tasks, but in real value delivering functionality.
Developer Morale
Developers are focussed on producing the next valuable item. They get MVP feedback in three months as opposed to three years and continuous feedback after that. True agility exists when the distance between prioritization-code-delivery-feedback is minimized. Developers not only get feedback but also the sense of accomplishment of delivering customer value. Soon, they start gaining that sense of accomplishment based on solving business problems and not just delivering features since delivering features is a daily thing.
Architects are a part of the team, and hence the technical decisions are pushed to the team level. Developers are in charge of their own destinies. they are not beholden to a central decision-making body that drops the gavel on what they can and cannot do. They have the ability to solve the problems in front of them the best way possible and have experienced architects on the team to consult. In summation, developers get to deliver value and get feedback, are in charge of their own technical destinies and get to solve the problems before them the best way possible. If any developer is unhappy in those surroundings, they probably need to look for an architect job at a company doing a three-year project.
(Short Term) Predictions
As opposed to figuring out what we can get done in three years and then making promises on those predictions, we move to a more tenable world. We start operating under a steady flow of value to the customer and make predictions on what we can get done in the next week or month. Sure, it makes long-term roadmap planning difficult, but that is for a good reason. Long term roadmap planning is based on a central assumption - We know everything that the customers want at the beginning of the project. I hope that in the modern day, no one believes that to be true for any decent length of time. Our ability to inspect and adapt in the short term is what is going to differentiate us from our customers. This ability gets severely undermined when we make long-term projections that bind us into promises and commitments that stop us from doing the most valuable things for our customers. We can be a lot more flexible and deliver the most valuable functionality as opposed to being locked into untenable promises.
Ending The Project
The product is at all times, after the MVP delivery, in a ready state. We are always delivering and validating what we assume to be the next highest value outcome. At some point though, what is the next highest value outcome for this product or project might not be the highest value outcome for the company. We might have also figured out, pretty early that this product was really not as valuable as we initially thought. Rather than sinking 3 years into this product we can actually end the project early and still have something that gives us return on investment. Instead of waiting to find out we have very early results on whether what we are working on is valuable or not. The very first assumption we make when we start work on a project or a product is that this has value. We need to find out if that is the case. Incremental and iterative delivery helps us find out as early as possible if that is true. It also provides us with multiple exit points from the project. We can exit at any point where we believe that any further investment in the product would be less valuable than investment somewhere else. This is in contrast with a "sunk cost " thinking in a 3-year project where there is only one easy exit point, at the end of the three years.
Also...
The Value Proposition
There is the small matter of making money. Imagine if delivering one-sixth of the product at 6 months can help you charge one-sixth of the projected price. At every six month increment, you can up the price by one-sixth of the projected price, till you are charging the same price as you expected at the end of the three-year term. This billing scheme would mean that by the time you end the fourth year of the project, you would have made almost twice the amount of money with the iterative scheme. Of course, there are assumptions here that this billing scheme is possible. There probably wont be as many customers signing on to the earlier versions. The billing scheme could be better than the one proposed here to make up for the fewer customer sign ups early on. More than the early and added return on investment, we actually find out very early if we are building something that people would be willing to pay for.
But My Project Is "Different"
None of this is to say that there are no successful three-year projects. I have been involved in multi-year projects before. Even in those, we went to production halfway through the proposed timeline with half the functionality and continued to release every day. We included customer feedback in prioritization. If I were to do the project again, I would have done it slightly differently and gone to production with real customers much earlier. As early as 10% of the functionality being done, that is probably the point where our MVP was. We were lucky though, the traditional organization elements of architecture and project management left us alone for the most part. It helped, but going to market early would probably have helped even more. Long running projects can be successful, but I am willing to bet that the same project, when done iteratively, and brought truly to production earlier would be a lot more on the mark and truly deliver the benefits of agile development.
In my estimation (I don't have hard proof on this), about 98% of the projects can be done in this iterative manner. Unless you are putting a man in space and have no way to user test it, this approach of going to market with 10% of the product, would benefit greatly. It could help even an otherwise successful project be even more successful. If you, the person reading this, believe that your project falls in the 2% case, there is a pretty good chance that you are mistaken. Most likely, you can define the MVP for your project, release it and then grow it. Yes, there are reasons to do it the other way, sure, there are people to convince, of course, it is a hard sell, but I am hoping we can agree that it is worth a try.
...But We Have Agile Teams
Yes, there is room for agile teams in long running projects. Unfortunately, most of the time, this is just teams running really fast in what is assumed to be the right direction. This assumption is not validated till late. Also, in a traditional organizational structure, with multiple levels of management, traditional PMO, top-heavy architecture org, expert consultants and zero contact between developers and end users, these teams are nothing but sports cars in a traffic jam. Yes, they can go really fast, but they cannot move anywhere. The core tenant of Agile - Inspect and Adapt, does not exist at the most important level. We are not actually taking the product to market and inspecting the results and changing course. We are instead relying on heavy up-front analysis and design. In complex systems, iteration would beat analysis any day.
The funny part is that these teams are set up to fail in the context of a system that is anything but agile. They are asked to be agile, to produce products fast and with high quality. Meanwhile, they live in the center of a system, where results and timelines are pre-determined. The system is set up to not validate assumptions. The teams might be agile, but the system being traditional undermines that agility. Attempts are made to make the team "more" agile and to fix their processes. That, in itself, is a waste of the company’s resources, as the real agility is needed at the top levels of management. An agile management team would allow the entire system to be optimized for early and frequent delivery.
Finally
If you are in the middle of a long project that is scheduled for a big bang release, there is still time to pivot. It will be a little messy, but in my opinion completely worth it. You will have to figure out what the MVP would look like. Make hard choices about which current features in progress to throw away. Maybe even reduce the size of the team in order to get focused on what is needed for the MVP. The good news is you have a start already and potentially are at a point where with some finishing touches, you can actually put together an MVP. Once that is in its place, it is a matter of delivering value as quickly as possible. Yes, if the company does not have a safe culture, this could be politically hazardous to attempt. After all, in the absence of safety, influencing change and doing the right thing is often a personal and a political risk.
There are no individuals that intend for a project to be a failure. The system, in the case of a big bang project, is set up for failure (or "less success"). Individuals are doing their best to make things happen based on what they are asked to do. Regardless of whether they are developers, architects, management or project managers, they all are working hard towards success. The system though is set up to be in their way. It is in the best interest of not just the company but the employees for us to switch to a more iterative approach.
Also, in this post, 3 years and 3 months are just an example. This is context specific. In your context, a long-running project could be 6 months and MVP be 2 weeks. Anything with no delivery for over a year though, in most cases, should be considered a long-running project.
A couple weeks ago, at Music City Agile I attended a session on combating biases presented by Neem Serra. There was a slide presented that had data from simulations on how gender bias during promotions affects the number of women at different levels of an organization. This was something that seemed to be simple to model and hopefully prove out. Around the same time, my wife became more active in the Women In Leadership events that my company regularly organizes. I have definitely experienced a raising of consciousness about the obstacles faced by women in IT and wanted to put some numbers behind this newfound consciousness.
Most of the conversation about gender bias centers around the pay gap. This is a legitimate concern and a good deal has been written about it. In this post, the exploration is centered around a slightly different question - What is the effect of gender bias in promotions through the hierarchy in an IT organization? In order to do this, we are going to set up a very simple mathematical model. We are going to start with the assumption that we are looking at an organization that has 5 levels of hierarchy, ie, line level folks are at level 1 and C-Level execs at level 5. Let us also say that in this organization, every couple of years 10% of the workforce at every level gets promoted to the next level. We are going to start with the case that the lowest level of the hierarchy has 50,000 women and 50,000 men. For the first run of our model, we will assume there is no (0%) gender bias shown during promotions. So, our starting model has the following assumptions -
Organization has 5 levels of hierarchy.
50,000 Women and 50,000 Men at the entry/line(first) level.
10% of employees at every level receive promotions.
0% promotion decisions have Gender Bias
The resulting numbers would look like this -
Level
Women
Men
Promotions
Percentage Of Women
Percentage Of Men
1
50000
50000
10000
50%
50%
2
5000
5000
1000
50%
50%
3
500
500
100
50%
50%
4
50
50
10
50%
50%
5
5
5
1
50%
50%
What we see in this case is that when there is no bias involved, the percentage of women at every level equals the percentage of men. With every round of promotions, the same number of women and men get promoted. Let us change our model to include some degree of bias. We will start with the case that there is a 10% gender bias. This would be reflected in 10% of promotion decisions involving women and 5% overall showing the bias. In other words, 5% of the promotions that should have gone to women, are actually handed to men due to conscious or sub-conscious bias. We are going to factor the bias in for promotions at every level. This time our model has this one parameter changed, and hence the following assumptions -
Organization has 5 levels of hierarchy.
50,000 Women and 50,000 Men at the entry/line(first) level.
10% of employees at every level receive promotions.
5% promotion decisions have Gender Bias
This has the following effect on the results -
Level
Women
Men
Promotions
Percentage Of Women
Percentage Of Men
1
50000
50000
10000
50%
50%
2
4500
5500
1000
45%
55%
3
405
595
100
41%
60%
4
36
64
10
36%
64%
5
3
7
1
33%
67%
The percentage of women at every subsequent level gets worse. When we finally reach the fifth level, we have only about 30% women holding office. The change is drastic compared to the base model with no bias. This should not be a surprise as in many organizations, the ratio of women in the highest echelons seems to be lower than at the entry level positions. If we change the bias to be affecting 10% of promotion decisions as opposed to 5%, we get the following results -
Level
Women
Men
Promotions
Percentage Of Women
Percentage Of Men
1
50000
50000
10000
50%
50%
2
4000
6000
1000
40%
60%
3
320
680
100
32%
68%
4
26
74
10
26%
74%
5
2
8
1
20%
80%
Once we change the bias to 10%, by the time we get to the fifth level of the organization, the percentage of women drops dramatically to close to 20%. Having 5 levels of hierarchy is actually a great simplification for most organizations. Usually, there are 7 or more levels separating the C-Level executives from the line level employees. The more levels we add, the more drastic the decrease in percentage becomes.
Another simplification in our modeling is assuming equal numbers of men and women in the industry. According to CNET, the percentage of women working in the tech industry is about 30. Our models, till now, have assumed an equal (at least at the starting level) ratio of men and women. What if we change the number of level one employees to reflect this. Also, let us assume bias being a factor in 10% of the promotions. Our model setup is now the following.
Organization has 5 levels of hierarchy.
30,000 Women and 70,000 Men at the entry/line(first) level.
10% of employees at every level receive promotions.
10% promotion decisions have Gender Bias
This renders the following results -
Level
Women
Men
Promotions
Percentage Of Women
Percentage Of Men
1
30000
70000
10000
30%
70%
2
2400
7600
1000
24%
76%
3
192
808
100
19%
81%
4
15
85
10
15%
85%
5
1
9
1
12%
88%
The number of women at the top level in this type of an organization drops drastically to 12%. Incidentally, the research at Paysa.com suggests that the percentage of female C-Level executives is close to 12% and the percentage of tech directors (Encapsulated by Level 3 in this case) is close to our model's 19%.
The numbers from our model matching the industry numbers is partly coincidental. We have made numerous assumptions in our modeling. The 10% promotion rate, same bias at every level, the number of levels in an organization are all assumptions in the model. These numbers do point to the existence of gender bias in the tech industry. Based on our simplifications, it seems that about 10% of the promotion decisions are affected by this bias. You can see what a drastic effect this has on an organization's makeup.
It would be interesting to see how individual organizations stack up. How consistent is the percentage of women as you move up the rungs of the corporate ladder? How about your organization? Does it seem that the ratio of women to men seem to get smaller the further up the organization you go? The culture of organizations is a product of the culture of the individuals that make up the organizations. As individuals it is up to us, to educate ourselves and reduce the role of bias in our own thinking. Neem Serra, whose session inspired me to play with the mathematics of bias, in her session also mentioned Harvard's Project Implicit. Project implicit helps you test for different kinds of biases. So far I have been brave enough to test myself only for gender bias and am pleased to say that the results said that I was unbiased in that regard. Take the tests for yourselves and see where you land on the bias spectrum. If there is work to be done, maybe spending some time with the folks you might hold a bias against would help.
A final note - This mode of modeling (applying bias as a percentage) and interpreting the results (tracking changes in percentages of members at every level) can be applied to any type of bias. This does not have to be restricted to gender and can be expanded to test for biases with regards to race, ethnicity, sexual orientation etc.